转摘首发!LLM的自动引用与自我纠正方法
泻药。最近都在讨论大模型怎么结合外部知识,但是都没人关注怎么用外部知识让模型的生成变得更准确。其实让LLM更准确,只要找到模型生成的对应的外部知识即可。如果生成答案的时候不结合外部知识,就可以用post-hoc方法去用外部知识修改模型生成的答案;如果生成答案的时候结合了外部知识,则要想办法让外部知识不影响模型生成答案的流畅度,同时提高模型的准确性。这两种方法各有优劣。
下面的三篇文章详细地探讨了这个问题。第一篇分析了最火的几个生成式搜索引擎(如bing)的现状,并且正式定义了模型引用文章的任务。第二篇提出了结合外部知识来生成带有引用的回答的方法,也就是LLM的自动引用机制。第三篇提出了先脱离外部知识生成回答,再使用外部知识对生成的回答进行纠正的方法,也就是LLM的自我纠正方法。让我们一篇一篇读过来。
人工评估:《评估生成搜索引擎的可验证性》
论文地址:[https://arxiv.org/pdf/2304.09848.pdf](https://link.zhihu.com/?target=https://arxiv.org/pdf/2304.09848.pdf)
生成式搜索引擎直接生成对用户查询的响应以及内嵌引用。可信赖的生成搜索引擎的先决条件是可验证性,即系统应该引用全面 (高引用召回率;所有陈述都得到引用的完全支持)和准确 (高引用精度;每个引用都支持其相关陈述)。我们进行人工评估 ,以审核四种流行的生成搜索引擎在不同场景下的性能(Bing Chat、NeevaAI、perplexity.ai 和 YouChat)。我们发现,现有的生成搜索引擎的响应是流畅的并且看起来信息丰富,但经常包含不受支持的陈述和不准确的引用:平均而言,只有 51.5% 的生成句子得到引用的完全支持,只有 74.5% 的引用支持其相关句子。我们认为,对于可以作为信息搜索用户主要工具的系统来说,这些结果非常低,尤其是考虑到它们的可信度。我们希望我们的结果进一步推动可信赖的生成搜索引擎的发展,并帮助研究人员和用户更好地了解现有商业系统的缺点。
换句话说,引用有的不全(理解为citation recall),有的不准确(理解为citation precision)。本文介绍了人工评估这些生成搜索引擎的结果。
  图 1 一个搜索引擎产生的带有嵌入式引用的例子
评价指标
本文评价了四个指标
- Fluency 流畅性
- Perceived Utility 有用性
- Citation Recall 全面性
- Citation Precision 准确性
如何建模这个问题?文章给出了评价指标的正式定义。观察图 1,我们发现引用是嵌入在回答中的。我们将用户的查询表示为 q ,将机器的回答表示为 r 。我们将机器的回答拆分为一个声明集 S=\{s_1,\cdots,s_n\} ,然后对于每个声明 s_i ,我们构造一个可能存在的引用集 C_i=\{c_{i1}, c_{i2}, \cdots, c_{ik}\} 。对于每个引用 c_{ij} ,存在两个信息:URL表示为 u_{ij} ,内容表示为 p_{ij} 。在进行评估的时候,我们希望声明集 S 越完整越好,但是必须是check-worthy的。也就是说,非常明显的事实不需要加入声明集。
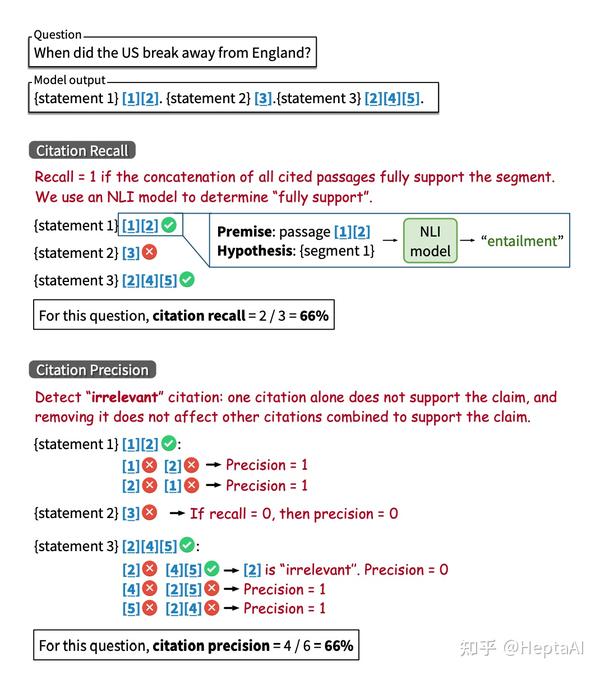
下面是一个评估recall和precision的metric的展示:
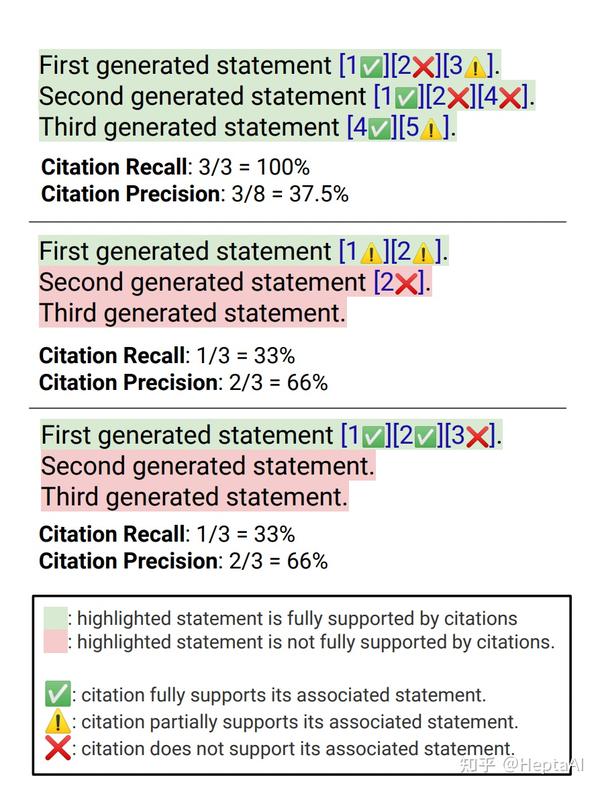  图 2 标注metric例子
为什么第二张图和第三张图的recall是一样的呢?因为所有check-worthy的statement拼起来形成的set S 会作为recall的分母,而评估者认为第二条statement并没有被它的citation支持,因此分数还是只能算一条的。因此recall的分子只能包含被支持的句子。
precision更简单一点,就是支持statement的citation总量除以所有的citation总量。
有了recall和precision,可以获得F-1分数:
 
数据集
文章标注用到的数据集如下:
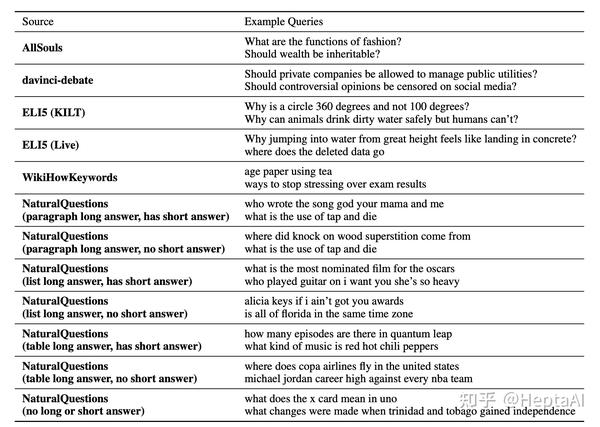  图 3 数据集与例子
结果
fluency结果:
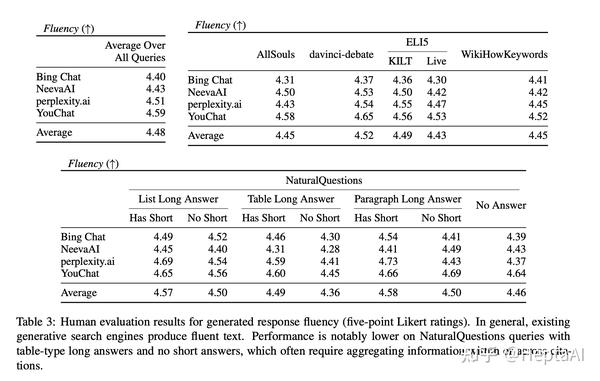 
- 生成的响应很流畅并且看起来很有帮助。表 3 展示了生成搜索引擎对我们每个查询分布的响应的流畅性,表 4 展示了感知效用。汇总所有系统和所有响应的注释器评分,流利度平均评分为 4.48,感知效用平均评分为 4.50,这表明注释器判断生成的响应流畅且有助于回答用户的输入查询。
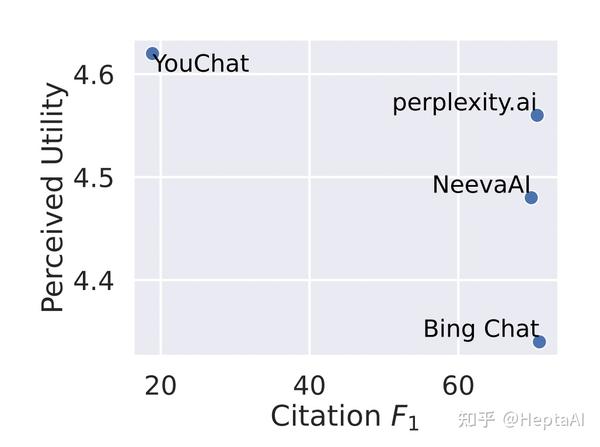
- 比较生成搜索引擎之间的流畅性和感知效用。比较生成搜索引擎之间的流畅度和感知效用评分(汇总所有响应),我们看到 Bing Chat 获得最低的流畅度/感知效用评分 (4.40 / 4.34),其次是 NeevaAI (4.43 / 4.48),perplexity.ai ( 4.51 / 4.56) 和 YouChat (4.59 / 4.62)。
- 比较查询分布的流畅性。比较不同查询分布的平均流利度评分,我们看到具有长答案的 NaturalQuestions 查询(即维基百科上存在一定长度的提取答案)和非 NaturalQuestions 分布(分别为 4.50 和 4.47)之间的评分相似。比较 NaturalQuestions 子分布之间的平均流利度评分,我们看到生成的对具有简短提取答案的查询的响应通常比对只有长答案的查询(4.46)或没有长答案的查询(4.46)的响应更流利(4.55),也许是因为对简短答案的问题的回答通常较短,而且通常只需要事实知识。
- 一个值得注意的离群分布是 NaturalQuestions 查询,它具有表格类型的长答案而没有简短答案,其中系统响应非常不流畅(跨系统的平均值为 4.36,而所有查询分布的平均值为 4.48)。这些具有挑战性的查询通常需要跨表格单元格或检索到的来源汇总信息,因为缺少简短答案意味着没有一个维基百科表格单元格可以直接回答问题(例如,查询"碧昂丝没有命运的孩子有多少格莱美奖")。当检索到的网页不包含对查询的明确提取答案,但包含看似相关的事实(例如,有关 Destiny Child 的第一个格莱美奖的信息,或 Beyonce 的职业格莱美奖总数),生成的响应可能会成为一个生硬的聚集来自各种来源的陈述,降低了整体流畅度。
- 比较跨查询分布的感知效用。另一方面,不同查询分布之间的感知效用可能有很大差异。与非 NaturalQuestions 查询 (4.43) 相比,包含长答案 (4.59) 的 NaturalQuestions 查询的感知效用要高得多。比较不同的 NaturalQuestions 子分布,我们发现感知效用对于具有简短答案的查询 (4.62) 最高,其次是只有长答案的查询 (4.55),最后是没有长(或短)答案的查询(4.52)。总体而言,随着查询需要更长形式和更少提取的答案(例如,具有简短答案的事实型 NaturalQuestions 查询与 ELI5 查询相比,感知效用会降低)。
recall结果:
precision结果:
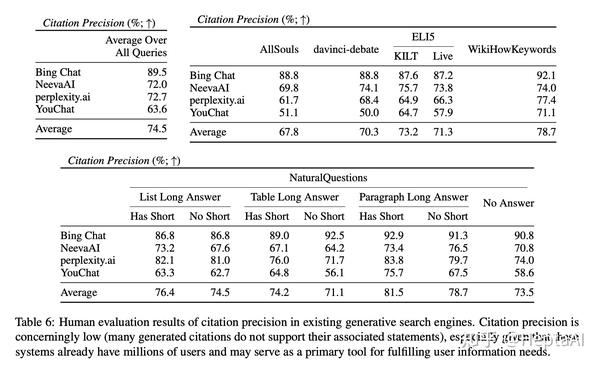 
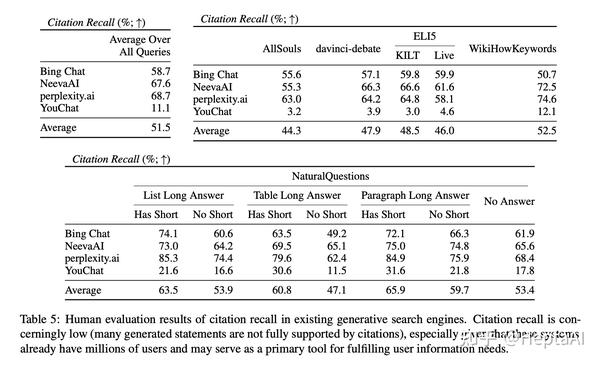
- 现有的生成搜索引擎往往引用不全面或不正确。当对所有系统进行平均时,只有 51.5% 的生成语句得到引用(召回)的完全支持,只有 74.5% 的引用完全支持其相关语句(精度)。我们认为,对于正在迅速成为回答用户查询的流行工具并且已经拥有数百万用户的系统来说,这些结果低得令人无法接受,尤其是考虑到生成的响应通常显得信息丰富且有用。
- 比较生成搜索引擎之间的引用召回率和精确率。不同的生成搜索引擎之间的引文召回率和精确率差异很大。平均而言,与 NeevaAI (67.6)、Bing Chat (58.7) 和 YouChat (11.1) 相比,perplexity.ai 的平均召回率最高 (68.7)。另一方面,Bing Chat 的准确率最高 (89.5),其次是 perplexity.ai (72.7)、NeevaAI (72.0) 和 YouChat (63.6)。召回率最高和最低的系统(perplexity.ai vs. YouChat)之间的差距接近 58%,精度最高和最低的系统之间的差距接近 25%(Bing Chat vs. YouChat)。
- 比较跨查询分布的引用召回率。修改评估查询分布似乎比引用精度更能影响引用召回率。例如,具有长答案的 NaturalQuestions 查询和非 NaturalQuestions 查询之间的引文召回率差距接近 11%(分别为 58.5 和 47.8)。同样,NaturalQuestions 查询有和没有简短答案的引文召回率差异接近 10%(简短答案查询为 63.4,只有长答案查询为 53.6,没有长答案或简短答案查询为 53.4)。我们假设引文召回是由检索到的网页的相关性驱动的。在没有直接回答输入用户查询的检索证据的情况下,系统会生成未经引用证实的陈述,从而导致较低的召回率。例如,在对开放式 AllSouls 论文问题(平均召回率为 44.3)进行评估时,生成搜索引擎在引用召回率方面遇到困难,因为这些查询在互联网上通常没有提取答案。
- 比较查询分布中的引用精度。具有长答案的 NaturalQuestions 查询的精度高于非 NaturalQuestions 分布(分别为 76.1 和 72.3)。检查单个查询分布的结果,生成搜索引擎在对具有段落答案类型的 NaturalQuestions 查询进行评估时具有最高的精度(当存在简短答案时精度为 81.5,当仅存在长答案时精度为 78.7)。另一方面,当系统在 AllSouls 开放式论文问题 (67.8) 和达芬奇辩论查询 (70.3) 上进行评估时,引用精度最低。比较 NaturalQuestions 子分布,具有简短答案的查询的平均系统精度 (77.4) 高于仅具有长答案 (74.8) 或没有长答案 (73.5) 的查询。
- 引文召回率和精确率与流利度和感知效用成反比:
一个定性的结果:
 
- 生成搜索引擎经常从引用的网页复制或严密解释。为了更好地理解生成搜索引擎如何使用引用来支持其响应,我们分析了生成的语句与其支持引用的网页之间的相似性。对于为其相关陈述提供全部或部分支持的引文,注释者被要求通过复制粘贴所引用网页中支持其判断的最少句子集(如果存在任何此类句子)来提供证据。我们采用具有提供全部或部分支持的相关引用的生成语句,并计算生成语句和引用证据之间的 BLEU(Papineni 等人,2002 年)和 BERTScore(Zhang 等人,2020 年)。对于具有多个关联引文的陈述,我们采用与任何关联引文证据的最大相似性,如下表所示
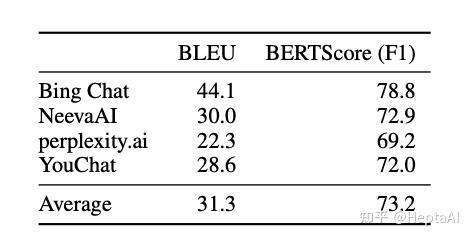
- 从 Internet 检索时,提取非常有效。
结合外部知识时生成:《使用LLM生成带有citation的text》
论文地址:[Enabling Large Language Models to Generate Text with Citations](https://link.zhihu.com/?target=https://arxiv.org/abs/2305.14627)
大型语言模型 (LLM) 已成为一种广泛使用的信息搜索工具,但它们生成的输出很容易产生幻觉 。在这项工作中,我们的目标是使 LLM 能够生成带有引用的文本,提高它们的事实正确性和可验证性。现有工作主要依赖于商业搜索引擎 和人工评估 ,因此很难复制和比较不同的建模方法。我们提出 ALCE,这是自动 LLM 引文评估 的第一个基准。 ALCE 收集各种问题和检索语料库,并需要构建端到端系统来检索支持证据并生成带有引用的答案。我们从三个维度(流畅性、正确性和引用质量)构建了自动指标,并证明了它们与人类判断的强相关性。我们对最先进的 LLM 和新颖的提示策略进行的实验表明,当前的系统有很大的改进空间------例如,在 ELI5 数据集上,即使是最好的模型也有 49% 的代缺乏完整的引用支持。我们广泛的分析进一步突出了有前途的未来方向,包括开发更好的检索器、推进长上下文 LLM 以及提高从多个来源综合信息的能力。
 
评估指标
准确度评估:
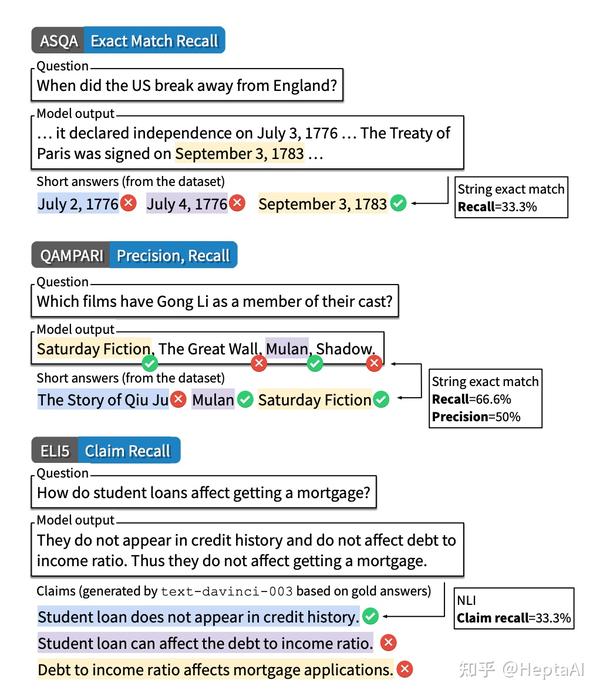 
引用质量评估:
自动评估方法
我们介绍了 ALCE,这是第一个可重复的基准,用于通过引用自动评估 LLM 的世代。 ALCE 假设一个自然语言问题和一个检索语料库,需要构建端到端系统从语料库中检索相关段落,生成对问题的回答,并引用相应的支持段落。我们收集了三个涵盖不同类型问题和语料库的数据集------ASQA(Stelmakh 等人,2022 年)、QAMPARI(Rubin 等人,2022 年)和 ELI5(Fan 等人,2019 年)------如下表。与之前的基准(Lee 等人,2019;Bohnet 等人,2022)不同,ALCE 评估长文本生成,侧重于自动评估引文质量,并允许为单个陈述引用多个段落。
 
我们设计了三个维度的自动评估方法:流畅性、正确性和引用质量。具体来说,我们使用 MAUVE (Pillutla et al., 2021) 来测量流利度,采用自然语言推理 (NLI) 模型 (Honovich et al., 2022) 来测量引用质量,并为每个数据集提出专门的正确性评估。我们展示了这三个维度如何共同促成稳健的评估,防止系统利用捷径。此外,我们进行人工评估并证明与我们的自动指标有很强的相关性。
Baseline方法
基本方法:
 
InlineSearch方法:
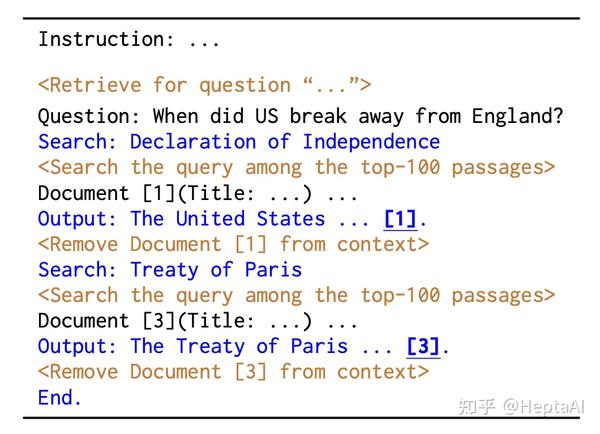 
本文主要的贡献是使用了几个prompt方法取得了不错的结果,然后设计了一个automatic evaluation的方法来进行评估。
先生成回应后结合外部知识修改回应:《研究和修改语言模型所说的内容,使用语言模型》
语言模型 (LM) 现在在许多任务中表现出色,例如问答、推理和对话。但是,它们有时会生成不受支持或具有误导性的内容。用户无法轻易确定他们的输出是否可信 ,因为大多数 LM 没有任何内置机制来归因于外部证据。为了在保留最新生成模型的所有强大优势的同时启用归因(attribution) ,我们提出了 RARR(使用研究和修订的改造归因),该系统 1) 自动为任何文本生成模型的输出找到归因 ,以及 2) 后期编辑输出以修复不受支持的内容,同时尽可能保留原始输出。当应用于一组不同的生成任务的几个最先进的 LM 的输出时,我们发现 RARR 显着改善了归因,同时在其他方面比以前探索的编辑模型更大程度地保留了原始输入。此外,RARR 的实施只需要少量训练示例、大型语言模型和标准网络搜索。
模型方法如下:
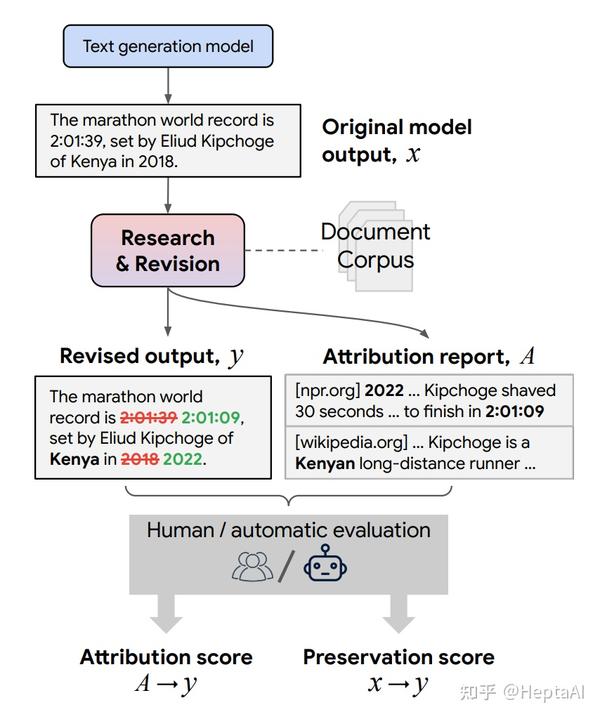 
更详细的模型说明:
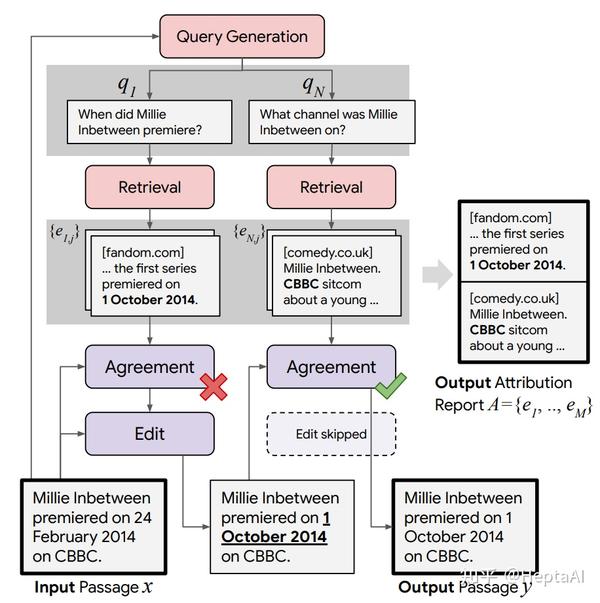 
prompt:
 
结果不错:
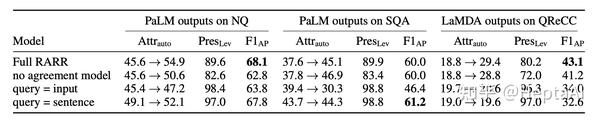 
这个模型是把相关内容丢到搜索引擎里面找,然后去纠正原文产生的问题,属于post-hoc方法。
```
===========================
【来源: 知乎】
【作者: HeptaAI】
【原文链接】 https://zhuanlan.zhihu.com/p/633326315
声明:转载此文是出于传递更多信息之目的。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本网联系,我们将及时更正、删除,谢谢。
```