翻译对高性能脉冲神经网络的人工神经网络架构进行基准测试
转载翻译自: https://www.mdpi.com/1424-8220/24/4/1329
论文标题: Benchmarking Artificial Neural Network Architectures for High-Performance Spiking Neural Networks
论文翻译
摘要
管理高性能计算系统的组织面临着众多挑战,包括总体能耗、微处理器时钟频率限制以及与芯片生产相关的不断上升的成本等主要问题。显然,处理器速度在过去十年中已经趋于稳定,一直保持在 2 GHz 至 5 GHz 的范围内。学者们断言,受大脑启发的计算对于缓解这些挑战具有巨大的希望。与传统设计范式相比,脉冲神经网络 (SNN) 尤其以其值得称赞的功率效率而脱颖而出。尽管如此,我们的审查揭示了阻碍在硅片上无缝实施大规模神经网络 (NN) 的几个关键挑战。这些挑战包括缺乏自动化工具、需要多方面的领域专业知识以及现有算法不足以有效地将大量 SNN 计算划分并放置在硬件基础设施上。在本文中,我们假设开发一种能够将任何 NN 转化为 SNN 的自动化工具流程。这项工作涉及创建一种新颖的图形分区算法,旨在将 SNN 战略性地放置在片上网络 (NoC) 上,从而为未来的节能和高性能计算范式铺平道路。所提出的方法成功地将 ANN 架构转换为 SNN,边际平均误差惩罚仅为 2.65%,从而展示了其有效性。所提出的图形分区算法平均可使突触间通信减少 14.22%,突触内通信减少 87.58%,凸显了所提出的算法在优化 NN 通信路径方面的有效性。与基线图形分区算法相比,所提出的方法平均延迟减少 79.74%,能耗减少 14.67%。使用现有的 NoC 工具,SNN 架构的能量延迟乘积平均比基线架构低 82.71%。
关键字:人工神经网络; ANN ;脉冲神经网络; SNN ;卷积神经网络; CNN ; ANN-to-SNN conversion; network-on-chip; NoC; 低能耗
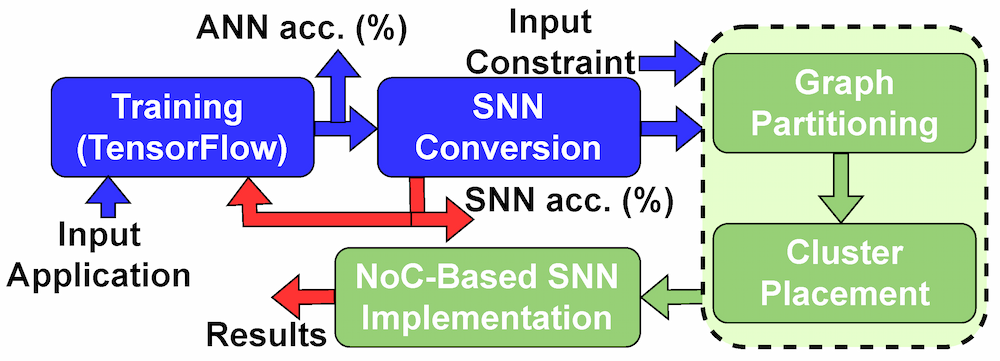
简介
脉冲神经网络 (SNN) [ 1 ] 代表了人工神经网络 (ANN) 进化的先锋,其灵感来源于生物有机体的复杂工作原理。与传统 ANN 相比,SNN 具有多项优势和独特功能,包括生物合理性,使其比 ANN 更具生物合理性。它们使用脉冲进行操作,类似于人类大脑中神经元的放电。此外,SNN 本质上是事件驱动的,这意味着它们仅在发生变化(脉冲)时才处理信息。这种事件驱动特性可以实现节能计算,尤其是在不需要连续处理的应用中。SNN 还可以通过脉冲的定时自然地捕获时间信息。这对于事件顺序和时间很重要的任务至关重要,例如在感官处理或动态模式识别中。最重要的是,SNN 中脉冲的稀疏性和二进制特性可以实现节能的硬件实现。这对于边缘计算和物联网设备中的应用尤其有利,因为功耗对于实现实时处理至关重要。与 ANN 相比,SNN 可以表现出对输入噪声的鲁棒性,因为它们基于脉冲的处理可以过滤掉不相关的信息。这对于输入数据可能具有固有噪声的应用非常有用。
然而,先进的神经网络范式在神经形态平台中得到了有效实施,这种平台的特点是多核系统,其中预定数量的神经元计算被精心映射到各个核心。这些神经元之间的通信通过突触实现,使用片上网络 (NoC) 结构进行协调——这是在多核系统内实现无缝通信的典型设计选择。在传统的 SNN 架构中,采用了类似于高速缓存架构 [ 1 ] 的非生物脉冲神经元和网格。神经元在超过其动作电位阈值后立即经历发放事件或脉冲产生,其中交叉开关充当突触权重的存储库 [ 2 ]。
基于 SNN 的计算系统的计算效率(以执行延迟和能耗衡量)取决于将神经元合理地分配给计算单元(即核心),同时将通信延迟降至最低。然而,输入负载和输出负载的电气约束限制了每个神经元的输入输出连接数量,因此需要通过 NoC 架构整合多个交叉开关。
在此背景下,将 SNN 单元计算组件映射到多核系统中的核心的现有算法方法需要更多地考虑底层 NoC 模型,以确保实现最佳通信延迟。此外,我们的研究还发现了在实际硬件系统上设计大规模 SNN 的多个关键挑战。这些挑战包括 (i) 缺乏构建可转化为硬件部署的软件级模型的综合指南,(ii) 缺乏设计自动化设备,迫切需要广泛的领域专业知识,以及 (iii) 现有神经元聚类方法的局限性,无法处理 SNN 中的大量神经元。本研究通过提供现有的图分区算法 [ 3 ] 并采用通用方法将 SNN 架构放置到 NoC 模型上来解决上述挑战。
在本文中,我们解决了当前图分区算法中存在的一个重大限制 [ 1 , 4 , 5 ],特别是对顶点数量的限制,该限制通常保持在 10,000 以下。我们介绍了一种新颖的贪婪图分区算法,该算法能够有效管理包含超过 100,000 个顶点的图,从而在集成到交叉开关硬件配置中时减少大量通信开销 [ 3 ]。具体而言,这项工作的主要贡献如下:
- 我们介绍了新颖的设计和自动化方法,该系统将任何神经网络架构转换为 SNN,以优化神经形态计算中的能源效率。
- 我们介绍了为实现广泛 SNN 而设计的新型图分区算法。
- 我们将分区的 SNN 架构映射到最先进的 NoC 工具流,以展示所提出方法的效率。
- 我们对多种深度神经网络 (DNN) 和卷积神经网络 (CNN) 架构进行基准评估,并无缝集成多个应用程序以证明我们的工具流的有效性。
- 与基线图分区算法相比,所提出的方法平均延迟减少了 79.74%,能耗减少了 14.67%。总体而言,与基线方法相比,所提出的方法平均能耗延迟乘积减少了 82.71%。
阅读原文
【转载翻译自】https://www.mdpi.com/1424-8220/24/4/1329
【声明】:
转载此文是出于传递更多信息之目的。
若有来源标注错误或侵犯了您的合法权益,请评论留言与本站联系,我们将及时更正、删除,谢谢。